Rethinking SSI
Since blockchain, decentralization has become a buzzword—and many of us still struggle to define what it really means to build fully decentralized systems. One key aspect often overlooked is trust. We cannot claim to have achieved decentralized infrastructure unless we also decentralize the trust model itself. That means going beyond central authorities and even beyond algorithmic “trustless” assumptions, toward Self-Certification as a foundational principle.
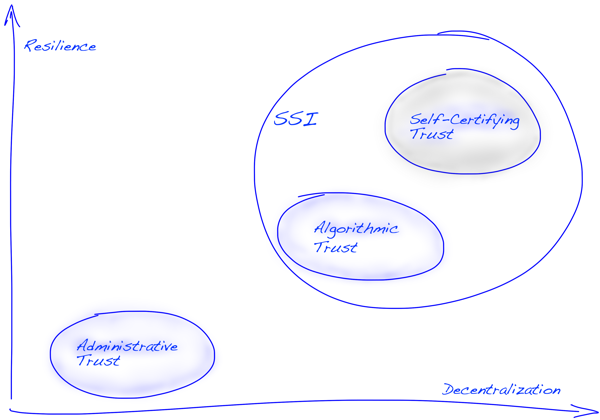
In the SSI space, three roots of trust have emerged:
- Administrative trust, as seen in traditional PKI (e.g., certificate authorities).
- Algorithmic trust, exemplified by blockchain-based systems—sometimes called “trustless,” though they still rely on pre-established consensus rules and protocols.
- Self-certifying trust, where entities define and prove trust relationships without requiring centralized or consensus-based validation.
Root of Trust Models — Foundations for Security & Sovereignty
This last model—self-certifying trust—is both the most ambitious and the most necessary if we are to realize the full potential of self-sovereign identity. From our experience, SSI will never become truly decentralized or user-controlled until we solve the challenge of enabling self-certifying roots of trust at scale.
This raises an important question: Should we approach identity-related use cases through an algorithmic zero-trust lens, or should we aim for a decentralized trust model based on self-certification?
Or should we simply build identity around PKI, as seen in current government-led approaches like the mobile Driver’s License (ISO mDL) or the EUDI Wallet? These systems rely on administrative trust models — and while they may not be decentralized, they offer well-understood security, strong governance, and user familiarity.
What seems increasingly clear is that these approaches are not mutually exclusive. To build inclusive, resilient, and user-friendly identity systems, we may need to combine the reliability of PKI, the resilience of algorithmic trust, and the sovereignty of self-certification. The future of identity likely lies in how well we can bridge and blend these trust models — not in picking one over the others.
Algorithmic Zero-Trust
Algorithmic zero-trust is a model where no actor is implicitly trusted, and all entities must continuously prove their authenticity and permissions through cryptographic or logical assertions. It’s common in enterprise security: access control decisions are made by policy engines based on signals like device health, IP reputation, or session risk.
In identity systems, zero-trust often implies constant re-verification, reliance on centralized attestations, and heavy use of encryption and secure channels. While secure and auditable, these systems are inherently closed and non-portable—they rely on predefined relationships and central policy evaluators, making them incompatible with open, permissionless ecosystems.
Zero-trust is effective when scope is limited, infrastructure is known, and risk can be algorithmically modeled. But it doesn’t support user-controlled identity, transitive trust, or cross-domain delegation—key goals in decentralized ecosystems.
Trust Based on Self-Certification
Self-certification flips the model. Instead of requiring a central verifier to approve every interaction, entities prove their claims through cryptographic self-assertions (e.g., signed DIDs, verifiable credentials, blinded signatures). Trust is not assumed—it’s earned or negotiated through transitive relationships and context-based reasoning.
In this model, identity becomes a fabric woven from peer-based attestations, localized trust decisions, and voluntary disclosure. Trust is not enforced by algorithms alone, but emerges from networks of autonomous actors—each defining their own trust domain.
This is the essence of the decentralized trust model: issuers, holders, and verifiers operate without centralized approval or universal agreement. Instead, trust arises through social proofs, credential provenance, and endorsement chains. It enables privacy, sovereignty, and interoperability—but also requires new tooling to reason about trust, detect fraud, and handle revocation and rotation.
Key Learnings from Real-World SSI Projects with Hyperledger Indy
These aren’t just technical findings — they’re observations about what truly matters when designing decentralized identity systems.
Decentralized Trust Is Hard to Scale
While Indy supports decentralized identifiers and verifiable credentials, scaling trust without introducing central authorities remains a major challenge. Transitive trust models — the foundation of any decentralized Web of Trust — lack global context and require custom trust policies per verifier. Bridging isolated trust domains without creating new chokepoints is still an open issue.
Why Symmetric Communication Matters
💡 From Sessions to Relationships
Traditional web services treat identity as a temporary session.
SSI flips the model: identity becomes persistent, portable, and relational.Instead of logging in, users bring their agent.
Instead of onboarding, services recognize credentials.
No accounts. No passwords. Just trust — established cryptographically,
remembered across time and channels.
The Internet was built on the client/server model — efficient, scalable, and simple. But it also created a core asymmetry: servers are persistent and authoritative; clients are ephemeral and disposable. This model has made it nearly impossible for users to maintain continuity across interactions without depending on centralized platforms.
Each time a client connects, it must authenticate itself from scratch. Persistent identity lives server-side, and the user is just a temporary session. This has contributed directly to the rise of centralized identity silos and the dominance of platform-centric Web2 services.
What if clients — or more accurately, identity agents — had persistent state of their own? What if they could maintain ongoing relationships with services, carry trust context across channels, and even operate across devices or over time?
Symmetric, peer-to-peer communication models like DIDComm make this possible. Instead of logging in and starting over, agents can resume where they left off — with long-lived, secure relationships that don’t require sign-ups, onboarding flows, or federated logins. Trust becomes transitive, contextual, and user-controlled.
This model reimagines the client not as a throwaway session but as a sovereign, persistent identity. And it enables a future where servers don’t need to authenticate every visitor — they can simply recognize known agents, verify their credentials, and interact accordingly. No password, no registration — just relationship-based trust.
Privacy Requires Active Design
Surveillance resistance and correlation avoidance aren’t free. Features like DID rotation, pairwise identifiers, and signature blinding are essential to prevent unwanted linkage between interactions. Most deployments still struggle with implementing these practices consistently.
Real Adoption Happens on the Web
Despite the ideal of sovereign identity wallets, most user adoption we observed (>95%) occurred via web-based identity wallets or embedded browser experiences (e.g., Trinsic). Native mobile or hardware wallets still face barriers to usability and integration.
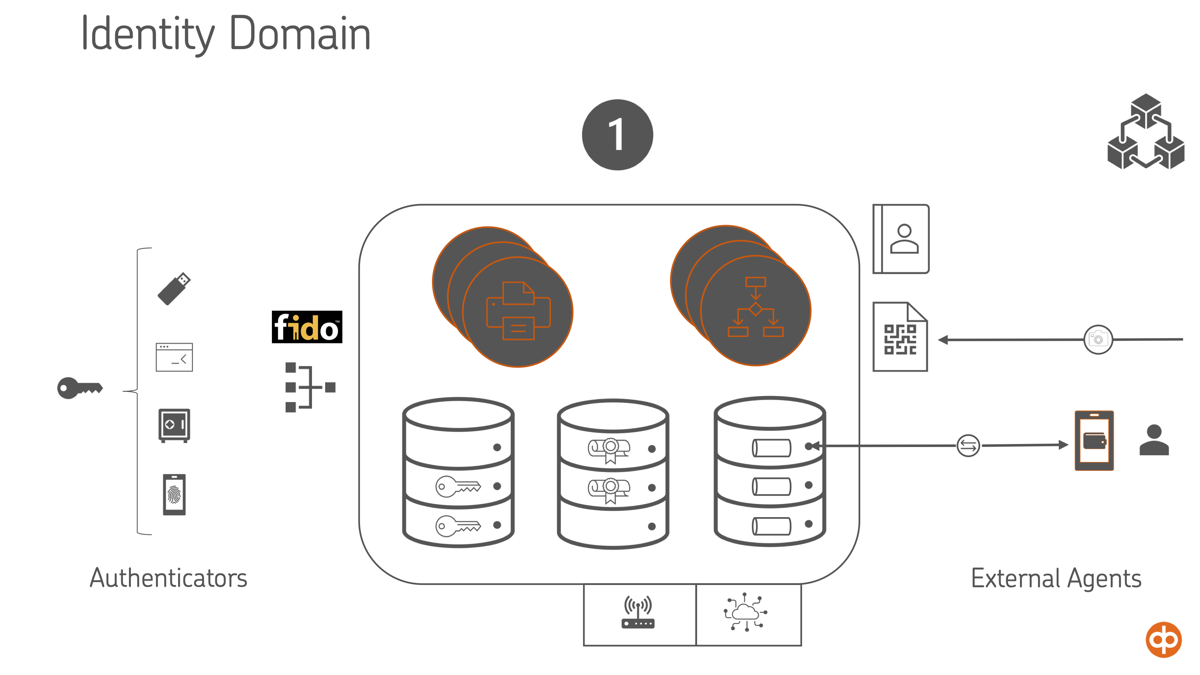
Identity Is More Than Credentials
In advanced use cases, identity extends beyond static credentials. We observed a growing need to bind biometric authenticators, behavioral data, credit scores, and reputational signals into a user’s Identity Domain. This domain becomes the source of trust for both human-facing and machine-mediated interactions.
Identity Domain — Spanning Layer and Hub
IoT and Edge Cases Are Not Edge Cases
IoT use cases — such as identity for machines, devices, or wearables — are real and growing. These actors often lack screens, keys, or user interfaces, requiring lightweight agents and trust protocols that work in constrained environments.
Revocation, Rotation, and Recovery Remain Fragile
Credential revocation, key rotation, and identity recovery are still brittle processes in most SSI systems. While the “SSI rule book” offers theoretical guidelines for these mechanisms, many are not grounded in operational realities or user behavior.
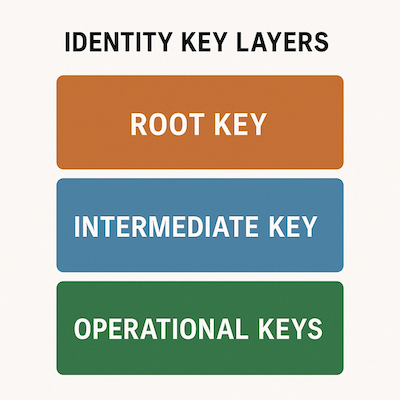
One key insight from our work is that treating key rotation as a holistic identity-level event is a mistake. Lessons from past decentralized systems—such as the PGP Web of Trust and Tor’s onion routing model—show that key hierarchies, delegation, and compartmentalized key usage are essential to managing trust and limiting key exposure over time.
Instead of relying on a single root key for an identity (and rotating it whenever anything changes), we should design systems where operational keys are short-lived, purpose-bound, and easily replaceable, with certification chaining providing continuity of identity without creating a single point of fragility.
Key Hierarchies — Key Certification Chaining
A self-sovereign identity system that cannot manage keys in a nuanced and layered way cannot scale. Identity needs to be resilient, renewable, and gracefully degradable—not brittle or tightly coupled to a single cryptographic anchor.
From Identity Agents to Autonomous Cyber Twins
As identities become programmable, identity agents are evolving into cyber agents — AI-driven entities that can manage trust relationships, negotiate disclosures, and even represent the user autonomously. These cyber twins could become persistent actors in decentralized ecosystems, handling everything from KYC to pseudonymous reputation management.
Looking Ahead
As the identity landscape continues to evolve, one thing is becoming increasingly clear: the need for a decentralized trust model isn’t just philosophical — it’s practical, and soon, existential.
Emerging technologies are rapidly moving toward autonomous, agent-based systems. From AI-powered identity agents to cross-domain agent-to-agent (A2A) protocols, the direction is set: machines will act on our behalf, negotiate access, and manage digital presence — sometimes entirely without human involvement.
But this vision only works if those agents can operate within a trust model that doesn’t require central control, universal agreement, or global consensus. That means trust must be self-certifying, transitive, and portable — grounded in cryptographic proofs and contextual relationships, not gatekeepers.
The biggest opportunity — and risk — lies here. If we solve the problem of self-certifying roots of trust, we unlock the next generation of agent-driven ecosystems: Cyber Twins that are privacy-preserving, pseudonymous, interoperable, and free to negotiate identity on behalf of their creators.
If we don’t, we’ll end up with a future where intelligent agents operate inside walled gardens, under opaque policies, bound by central authorities. That’s not self-sovereign identity — it’s algorithmic feudalism.
The box is opening. Let’s make sure what comes out is free.
