Deploying with CDK Pipeline
My previous post described how we have been using the native AWS IaC tools for defining and updating our PoC environment infrastructure. The story ended with taking AWS CDK v2 in use and switching the deployment process on top of CDK pipelines. In this article, I will describe the anatomy of our CDK pipeline in more detail.
Watch my “CDK-based Continuous Deployment for OSS” talk on AWS Community Day on YouTube.Self-Mutating Pipelines
CDK Pipeline offers a streamlined process for building, testing, and deploying a new version of CDK applications. It tries to simplify the developer’s life by hiding the dirty details of multiple services needed to build working pipelines in AWS. As usual with CDK tools, it provides no new AWS services but is a convenient abstraction layer on top of the existing AWS continuous integration and deployment products.
The main idea of the pipeline is that instead of the developer deploying the application from her local computer, a process implemented through AWS CodePipelines (CDK pipeline) handles the deployment. Thus, in the agency case, instead of me running the script locally to create all needed AWS resources for our AWS deployment, I create locally only the CDK pipeline, which, in turn, handles the resource creation for me.
The CDK pipeline also handles any subsequent changes to the deployment (or even in the pipeline process itself). Therefore, developers modify the CDK deployment only through version control after the pipeline creation. This feature makes it self-mutating, i.e., self-updating, as the pipeline can automatically reconfigure itself.
This model reduces the need for running the tools from the developer’s local machine and enforces a behavior where all the deployment state information is available in the cloud. Using CDK pipelines also reduces the need to write custom scripts when setting up the pipeline.
| CDK v1 | CDK v2 Pipelines | |
|---|---|---|
| Pipeline creation | Developer deploys from local | Developer deploys from local |
| Changes to pipeline configuration | Developer deploys from local | Developer commits to version control. CDK Pipeline deploys automatically. |
| Agency creation | Developer deploys from local | Developer commits to version control. CDK Pipeline deploys automatically. |
| Changes to Agency resources | Developer deploys from local | Developer commits to version control. CDK Pipeline deploys automatically. |
| Need for custom scripts | Storing of Agency deployment secrets and parameters. Pipeline creation with Agency deployment resource references. | Storing all needed secrets and parameters in pipeline creation phase. |
The use of CDK Pipelines converted the Agency deployment model to a direction where the pipeline does most of the work in the cloud, and the developer only commits the changes to the version control.
Agency Deployment
Regarding the agency deployment, we have a single CDK application that sets up the whole agency platform to AWS. A more production-like approach would be to have a dedicated deployment pipeline for each microservice. However, having the resources in the same application is handy for the time being as we occasionally need to set the agency fully up and tear it down rapidly.
If one wishes to deploy the agency to AWS using the CDK application, there are some prerequisities:
- The needed tools for Typescript CDK applications
- AWS Codestar connection to GitHub via AWS Console
- A hosted zone for Route53 for the desired domain
- Agency configuration as environment variables.
The setup process itself consists of two phases. Firstly, one must store the required configuration to parameter store and secrets manager. Secondly, one should deploy the pipeline using CDK tooling. I have written bash scripts and detailed instructions to simplify the job.
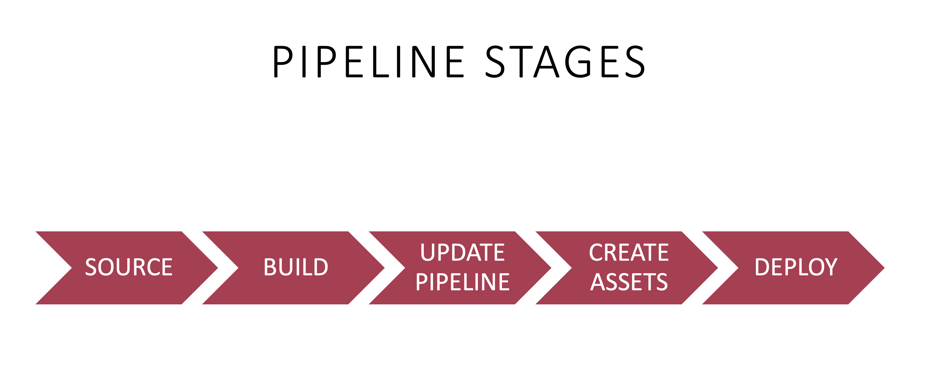
Pipeline Stages
Each CDK pipeline consists of 5 different stages. It is essential to have a basic understanding of these stages when figuring out what is happening in the pipeline. CDK pipeline creates these stages automatically when one deploys the pipeline constructs for the first time. The developer can modify and add logic to some stages, but mainly the system has a hard-coded way of defining the pipeline stages. This functionality is also why AWS calls the CDK pipelines “opinionated.” Therefore some projects will find the CDK pipeline philosophy for building and deploying assets unsuitable.
1/5 Source
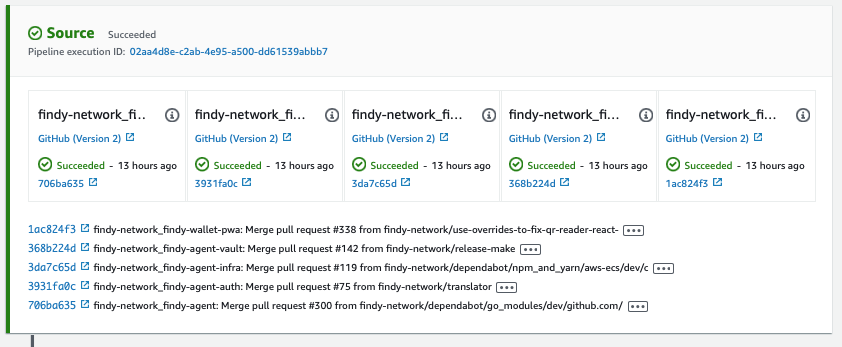
The source stage fetches the code from the source code repositories. In the agency case, we have five different source repositories in GitHub. Whenever we push something to the master branch of these repositories, i.e., make a release, our pipeline will run as we have configured the master branch as the pipeline trigger.
We don’t need the code for the backend services for anything but triggering the pipeline. We use only the front-end and infra repositories code to build the static front-end application and update the CDK application, i.e., the application containing the CDK code for the agency infrastructure and pipeline. GitHub actions handle building the backend Docker containers for us and the images are stored publicly in GitHub Packages.
2/5 Build
The build stage has two roles: it converts the CDK code to CloudFormation templates and builds any assets that end up in S3 buckets.
The developer can define this workflow, but the steps must produce the CDK synthesizing output in a dedicated folder. The phase when CDK tooling converts the CDK code to the CloudFormation templates is called synthesizing.
With the agency, we have some custom magic in place here as we are fetching the CDK context from the parameter store for the synthesizing. The recommendation is to store the context information in the CDK application repository, but we don’t want to do it as it is open-source.
Pipeline creation in the CDK application code:
const pipeline = new CodePipeline(this, "Pipeline", {
pipelineName: "FindyAgencyPipeline",
dockerEnabledForSynth: true,
// Override synth step with custom commands
synth: new CodeBuildStep("SynthStep", {
input: infraInput,
additionalInputs: {
"../findy-agent": CodePipelineSource.connection(
"findy-network/findy-agent",
"master",
{
connectionArn: ghArn, // Created using the AWS console
}
),
...
},
installCommands: ["npm install -g aws-cdk"],
...
// Custom steps
commands: [
"cd aws-ecs",
// Prepare frontend build env
"cp ./tools/create-set-env.sh ../../findy-wallet-pwa/create-set-env.sh",
// Do cdk synth with context stored in params
`echo "$CDK_CONTEXT_JSON" > cdk.context.json`,
"cat cdk.context.json",
"npm ci",
"npm run build",
"npx cdk synth",
"npm run pipeline:context",
],
...
// The output of the synthing process
primaryOutputDirectory: "aws-ecs/cdk.out",
}),
...
});
The building of assets happens automatically as part of the synthesizing. The pipeline orchestrates it based on the instructions that one defines for the deployment assets.
3/5 UpdatePipeline
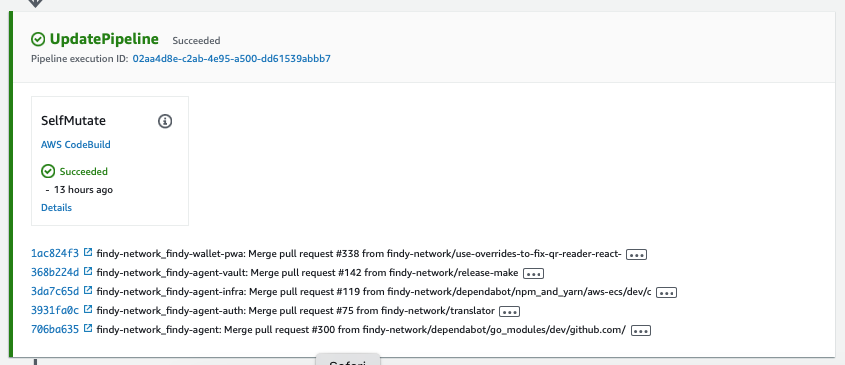
UpdatePipeline makes any changes to the pipeline, i.e., modifies it with new stages and assets if necessary. The developer cannot alter this stage. One thing to notice is that the pipeline process is always initially run with the currently saved version. If a change in the version control introduces changes to the pipeline, the pipeline execution is canceled in this stage and restarted with the new version.
4/5 Assets
In the assets stage, the pipeline analyzes the application stack and publishes all files to S3 and Docker images to ECR that the application needs for deployment. CDK Pipelines stores these assets using its buckets and ECR registries. By default, they have no lifecycle policies, so the CDK developer should ensure that the assets will not increase their AWS bill unexpectedly.
Assets building
utilizes aws-s3-deployment module for the frontend application:
// Source bundle
const srcBundle = s3deploy.Source.asset('../../findy-wallet-pwa', {
bundling: {
command: [
'sh', '-c',
'npm ci && npm run build && ' +
'apk add bash && ' +
`./create-set-env.sh "./tools/env-docker/set-env.sh" "${bucketName}" "${process.env.API_SUB_DOMAIN_NAME}.${process.env.DOMAIN_NAME}" "${GRPCPortNumber}" && ` +
'cp -R ./build/. /asset-output/'
],
image: DockerImage.fromRegistry('public.ecr.aws/docker/library/node:18.12-alpine3.17'),
environment: {
REACT_APP_GQL_HOST: bucketName,
REACT_APP_AUTH_HOST: bucketName,
REACT_APP_HTTP_SCHEME: 'https',
REACT_APP_WS_SCHEME: 'wss',
},
},
});
new s3deploy.BucketDeployment(this, `${id}-deployment`, {
sources: [srcBundle],
destinationBucket: bucket,
logRetention: RetentionDays.ONE_MONTH
});
5/5 Deploy
Finally, the Deploy stage creates and updates the application infrastructure resources. There is also a chance to add post steps to this stage, which can run the post-deployment testing and other needed scripts.

For the agency, we are using the post-deployment steps for three purposes:
- We have a custom script for updating the ECS service. This script is in place to tweak some service parameters missing from CDK constructs.
- We do the configuration of the agency administrator account.
- We are running an e2e test round to ensure the deployment was successful.
Conclusions
The CDK pipeline is initially a bit complex to get your head around. For simple applications, the use is easy, and there isn’t even a need to deeply understand how it works. However, when the deployment has multiple moving parts, it is beneficial to understand the different stages.
There are still some details that I would like to see improvement in. The documentation and examples need additions, especially on how to use the assets correctly. There have been improvements already, but complete example applications would make the learning curve for the CDK pipelines more gentle. They state that CDK pipelines are “opinionated,” but users should know better what that opinion is.
However, the CDK pipeline model pleases me in many ways. I especially value the approach that has reduced the steps needed to run in the developer’s local environment compared to how we used the previous versions of AWS IaC tools. Furthermore, the strategy enables multiple developers working with the same pipeline as the state needs to be available in the cloud. Finally, I am happy with the current state of our deployment pipeline, and it works well for our purposes.
If interested, you can find all our CDK application codes in GitHub and even try to deploy the agency yourself!