Replacing Indy SDK
Once again, we are at the technology crossroad: we have to decide how to proceed with our SSI/DID research and development. Naturally, the business potential is the most critical aspect, but the research subject has faced the phase where we have to change the foundation.
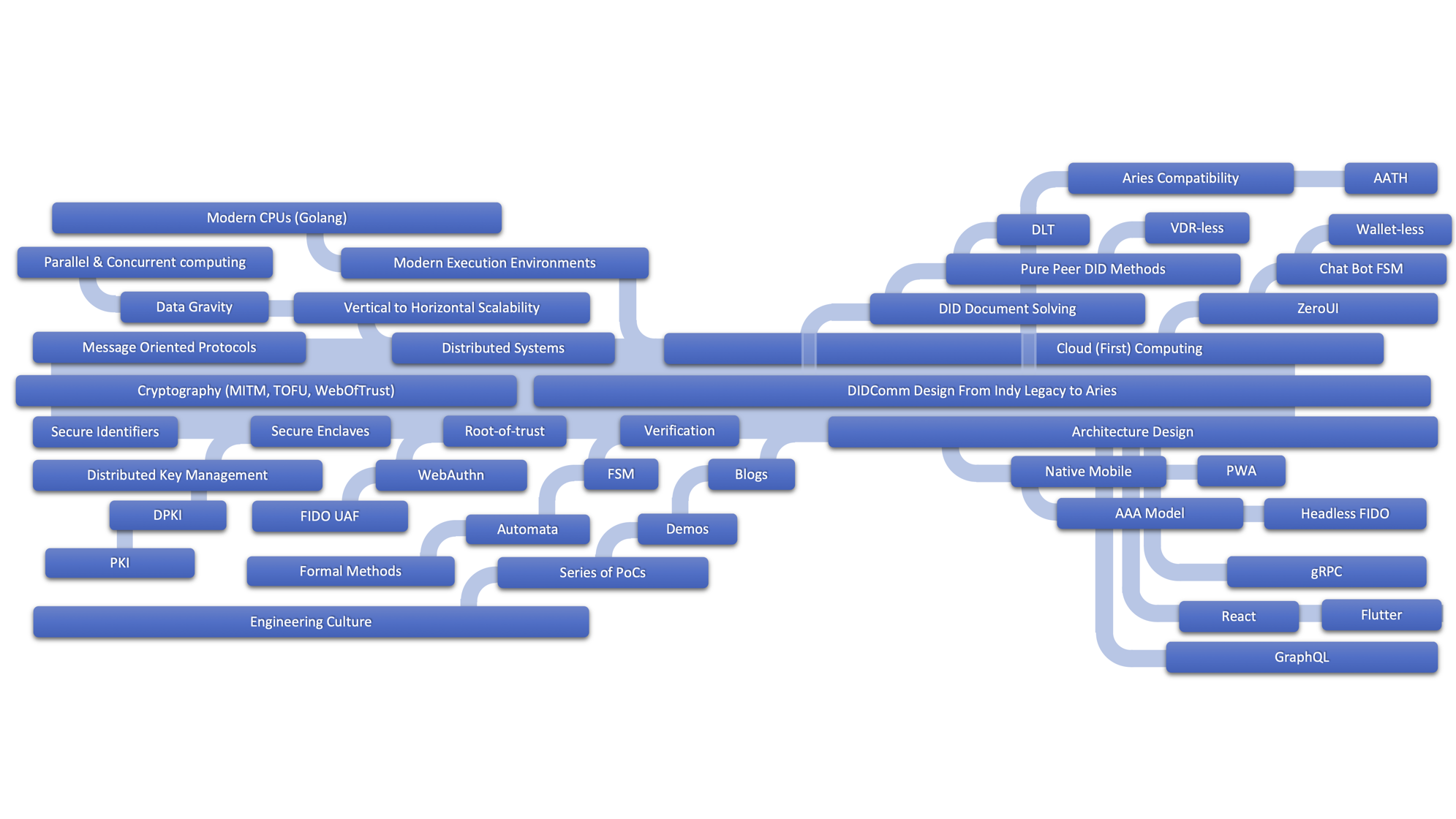
Our Technology Tree - Travelogue
Changing any foundation could be an enormous task, especially when a broad spectrum of technologies is put together. (Please see the picture above). Fortunately, we have taken care of this type of a need early in the design when the underlying foundation, Indy SDK is double wrapped:
- We needed a Go wrapper for
libindyitself, i.e. language wrapping. - At the beginning of the
findy-agentproject, we tried to find agent-level concepts and interfaces for multi-tenant agency use, i.e. conceptual wrapping.
This post is peculiar because I’m writing it up front and not just reporting something that we have been studied and verified carefully.
“I am in a bit of a paradox, for I have assumed that there is no good in assuming.” - Mr. Eugene Lewis Fordsworthe
I’m still writing this. Be patient; I’ll try to answer why in the following chapters.
Who Should Read This?
You should read this if:
You are considering jumping on the SSI/DID wagon, and you are searching good technology platform for your SSI application. You will get selection criteria and fundamentals from here.
You are in the middle of the development of your own platform, and you need a concrete list of aspects you should take care of.
You are currently using Indy SDK, and you are designing your architecture based on Aries reference architecture and its shared libraries.
You are interested to see the direction the
findy-agentDID agency core is taking.
Indy SDK Is Obsolete
Indy SDK and related technologies are obsolete, and they are proprietary already.
We have just reported that our Indy SDK based DID agency is AIP 1.0 compatible, and everything is wonderful. How in the hell did Indy SDK become obsolete and proprietary in a month or so?
Well, let’s start from the beginning. I did write the following on January 19th 2022:
Indy SDK is on the sidetrack from the DID state of the art.
Core concepts as explicit entities are missing: DID method, DID resolving, DID Documents, etc.
Because of the previous reasons, the API of Indy SDK is not optimal anymore.
libindyis too much framework than a library, i.e. it assumes how things will be tight together, it tries to do too much in one function, or it doesn’t isolate parts like ledger from other components like a wallet in a correct way, etc.Indy SDK has too many dynamic library dependencies when compared to what those libraries achieve.
The Problem Statement Summary
We have faced two different but related problems:
- Indy SDK doesn’t align with the current W3C and Aries specifications.
- The W3C and Aries specifications are too broad and lack clear focus.
DID Specifications
I cannot guide the work of W3C or Aries, but I can participate in our own team’s decision making, and we will continue on the road where we’ll concentrate our efforts to DIDComm, which will mean that we’ll keep the same Aries protocols implemented as we have now, but with the latest DID message formats:
- DID Exchange to build a DIDComm connection over an invitation or towards public DID.
- Issue Credential to use a DIDComm connection to issue credentials to a holder.
- Present Proofs to present proof over a DIDComm connection.
- Basic Message to have private conversations over a DIDComm connection.
- Trust Ping to test a DIDComm connection.
Keeping the same protocol set might sound simple, but unfortunately, it’s not because
Indy SDK doesn’t have, e.g. a concept for DID Method. At the end of the January
2022, no one has implemented the did:indy method either, and its specification is
still in work-in-progress.
The methods we’ll support first are did:peer and did:key. The first is
evident because our current Indy implementation builds almost identical pairwise
connections with Indy DIDs. The did:key method replaces all public keys in
DIDComm messages. It has other use as well.
The did:web method is probably the next. It gives us an
implementation baseline for the actual super DID Method
did:onion.
In summary, onion routing gives us a new transport layer (OSI
L4).
We all know how difficult adding security and privacy to the internet’s (TCP/IP) network layers are (DNS, etc.). But replacing the transport layer with a new one is the best solution. Using onion addresses for the DID Service Endpoints solves routing in own decoupled layer which reduces complexity tremendously.

“In some sense IP addresses are not even meaningful to Onion Services: they are not even used in the protocol.” - Onion Services
Indy SDK Replacement
Indy SDK is obsolete and proprietary. It’s not based on the current W3C DID core concepts. That makes it too hard to build reasonable solutions over Indy SDK without reinventing the wheel. We have decided to architect the ideal solution first and then make the selection criteria from it. With the requirements, we start to select candidates for our crypto libraries.
We don’t want to replace Indy SDK right away. We want to keep it until we don’t need it anymore. When all parties have changed their verified credential formats according to the standard, we decide again if we can drop it.
Putting All Together
We described our problems in the problem statement summary. We will put things together in the following chapters and present our problem-solving strategy.
First, we need to align our current software solution to W3C specifications. Aries protocols are already covered. Secondly, we need to find our way for specification issues like selecting proper DID methods to support.
The missing (from Indy SDK) DID core concepts: DID, DID document, DID method, DID resolving, will be the base for our target architecture. The following UML
diagram presents our high-level conceptual model of these concepts and
their relations.
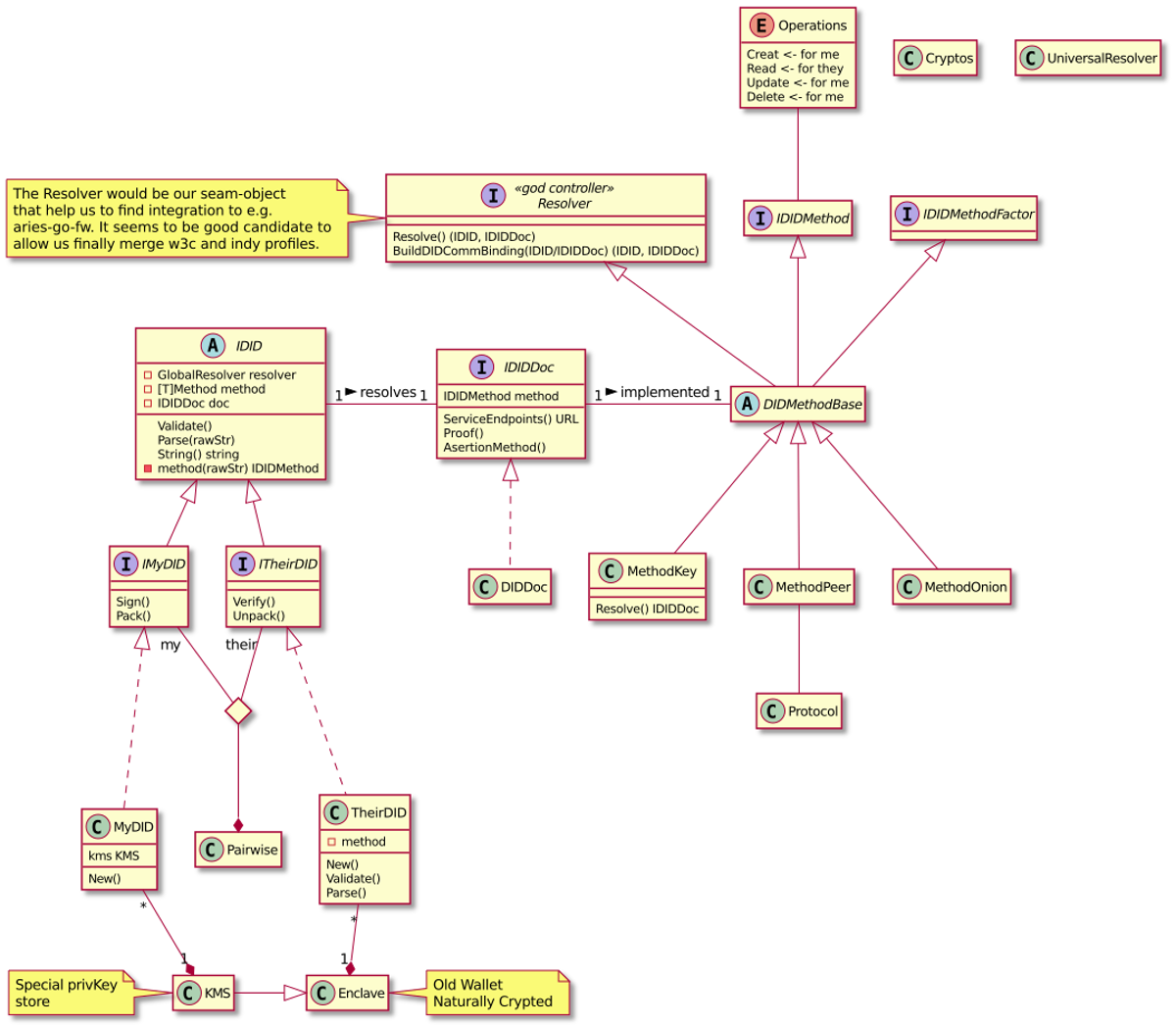
Agency DID Core Concepts
The class diagram shows that DIDMethodBase is a critical abstraction because
it hides implementation details together with the interfaces it extends. Our
current agent implementation uses factory pattern with new-by-name, which
allows our system to read protocol streams and implicitly create native Go objects.
That has proven to be extremely fast and programmer-friendly. We will use
a similar strategy in our upcoming DID method and DID resolving solutions.
Resolving
The following diagram is our first draft of how we will integrate DID document resolving to our agency.
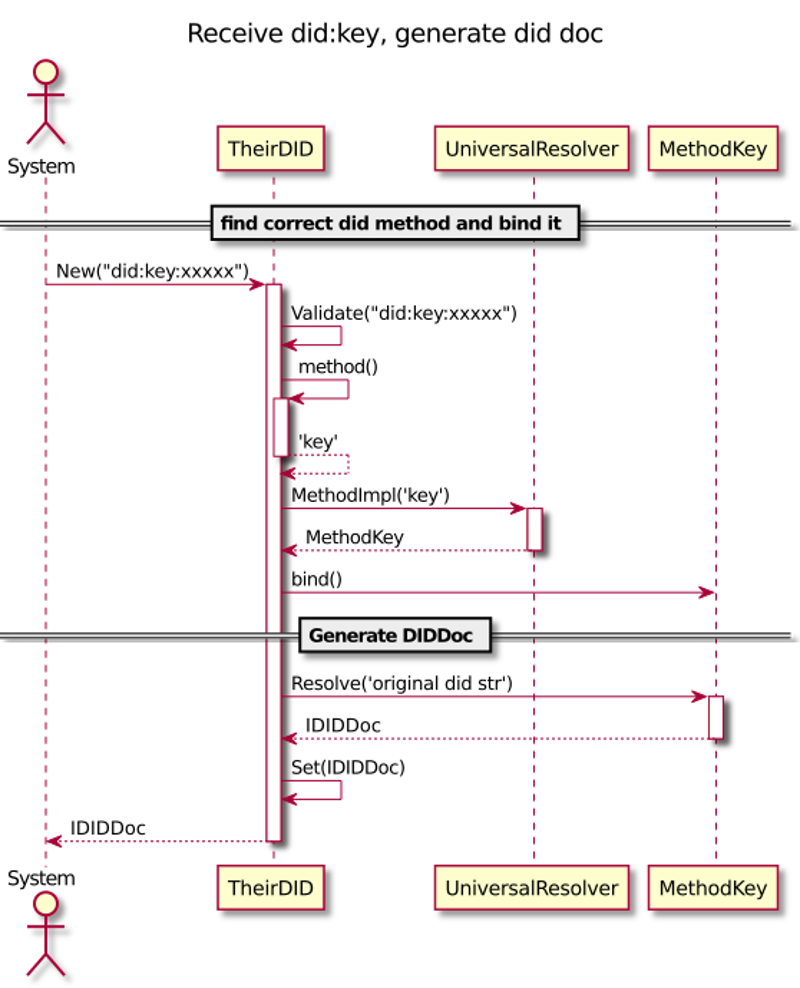
Agency DID Core Concepts
The sequence diagram is a draft where did:key is solved. The method is solved
by computation. It doesn’t need persistent storage for DID documents. However,
the drawing still illustrates our idea to have one internal resolver (factory)
for everything. That gives many advantages like caching, but it also
keeps things simple and testable.
Building Pairwise – DID Exchange
You can have an explicit invitation (OOB) protocol or you can just have a public DID that implies an invitation just by existing and resolvable the way that leads service endpoints. Our resolver handles DIDs and DID documents and invitations as well. It’s essential because our existing applications have proven that a pairwise connection is the fundamental building block of the DID system.
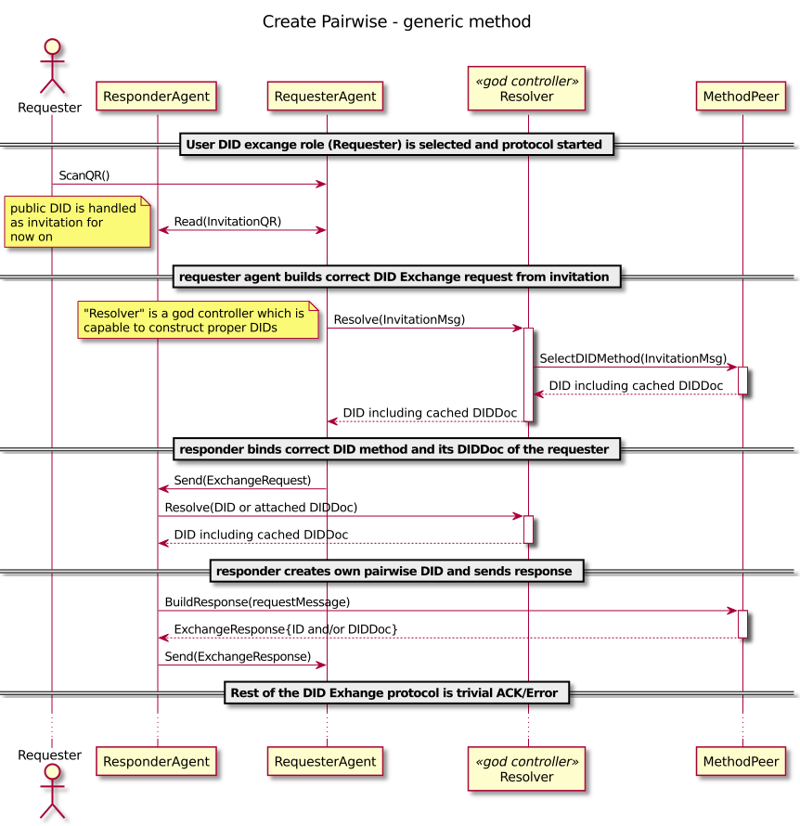
Agency DID Core Concepts
We should be critical just to avoid complexity. If the goal is to reuse existing pairwise (connection), and the most common case is a public website, should we leave that for public DIDs and try not to solve by invitation? When public DIDs would scale and wouldn’t be correlatable, we might be able to simplify invitations at least? Or, should we think if we really need connectable public DIDs? Or maybe we don’t need both of them anymore, just another?
Our target architecture helps us to find answers to these questions. It also allows us to keep track of non-functional requirements like modifiability, scalability, security, privacy, performance, simplicity, testability. These are the most important ones, and everyone is equally important to us.
Existing SDK Options?
Naturally, Indy SDK is not the only solution for SSI/DID. When the Aries project and its goals were published, most of us thought that replacing SDKs for Indy would come faster. Unfortunately, that didn’t happen, and there are many reasons for that.
Building software has many internal ’ecosystems’ mainly directed by programming languages. For instance, it’s unfortunate that gophers behave like managed language programmers and rarely use pure native binary libraries because we lose too many good Go features. For example, we would have compromised in super-fast builds, standalone binaries, broad platform support, etc. They might sound like small things, but they aren’t. For example, the container image sizes for standalone Go binaries are almost the same as the original Go binary.
It is easier to keep your Go project only written in Go. Just one ABI library usage would force you to follow the binary dependency tree, and you could not use standalone Go binary. If you can find a module just written in Go, you select that even it would be some sort of a compromise.
That’s been one reason we have to build our own API with gRPC. That will offer the best from both worlds and allow efficient polyglot usage. I hope others do the same and use modern API technologies with local/remote transparency.
We Are Going To Evaluate AFGO
Currently, the Aries Framework Go seems to be the best evaluation option for us because:
- It’s written in Go, and all its dependencies are native Go packages.
- It follows the Aries specifications by the book.
Unfortunately, it also has the following problems:
It’s is a framework which typically means all or nothing, i.e. you have to use the whole framework because it takes care of everything, and it only offers you extension points where you can put your application handlers. A framework is much more complex to replace than a library.

Difference Between Library and Framework - The Blog Post
Its protocol state machine implementation is not as good as ours:
It doesn’t fork protocol handlers immediately after receiving the message payload.
It doesn’t offer a 30.000 ft view to machines, i.e. it doesn’t seem to be declarative enough.
It has totally different concepts than we and Indy SDK have for the critical entities like DID and storage like a wallet. Of course, that’s not necessarily a bad thing. We have to check how AFGO’s concepts map to our target architecture.
During the first skimming of the code, a few alarms were raised primarily for the performance.
We will try to wrap AFGO to use it as a library and produce an interface that we can implement with Indy SDK and AFGO. This way, we can use our current core components to implement different Aries protocols and even verifiable credentials.
Our agency has bought the following features and components which we have measured to be superior to other similar DID solutions:
- Multi-tenancy model, i.e. symmetric agent model
- Fast server-side secure enclaves for KMS
- General and simple DID controller gRPC API
- Minimal dependencies
- Horizontal scalability
- Minimal requirements for hardware
- Cloud-centric design
We really try to avoid inventing the wheel, but with the current knowledge, we cannot switch to AFGO. Instead, we can wrap it and use it as an independent library.
Don’t call us, we’ll call you. - Hollywood Principle
We will continue to report our progress and publish the AFGO wrapper when ready. Stay tuned, folks, something extraordinary is coming!