The Missing Network Layer Model
The W3C’s DID Specification is flawed without the network layer model.
You might think that I have lost my mind. We have just reported that our Indy SDK based DID agency is AIP 1.0 compatible, and everything is wonderful. What’s going on?
Well, let’s start from the beginning. I did write the following list on January 19th 2022:
Indy SDK doesn’t align the current W3C and Aries specifications.
- Core concepts (below) as explicit entities are missing: DID method, DID resolving, DID Documents, etc.

DID Concepts - www.w3.org
No one in the SSI industry seems to be able to find perfect focus.
There are too few solutions running in production (yes, globally as well) which would give us needed references to drive a good design from.
Findings during our study of SSI/DID and others in the industry.
We don’t need a ledger to solve self-certified identities.
We don’t need human memorable identifiers. (memorable \(\ne\) meaningful \(\ne\) typeable \(\ne\) codeable)
We rarely need an identifier just for referring but we continuously need self-certified identifiers for secure communication: should we first fully solve the communication problem and not the other way around?
Trust always seems to lead back to a specific type of centralization. There are many existing studies like web-of-trust that should at least take in a review. Rebooting Web-of-Trust is an excellent example of that kind of work.
We must align the SSI/DID technology to the current state of the art like Open ID and federated identity providers. Self-Issued OpenID Provider v2 the protocol takes steps in the right direction and will work as a bridge.
W3C DID Specification Problems
Now, February 20th 2022, the list is still valid, but now, when we have dug deeper, we have learned that the DID W3C “standard” has its flaws itself.
It’s far too complex and redundant – the scope is too broad.
There should not be so many DID methods. “No practical interoperability.” & “Encourages divergence rather than convergence.”
For some reason, DID-core doesn’t cover protocol specifications, but protocols are in Aries RFCs. You’ll face the problem in the DID peer method specification.
It misses layer structures typical for network protocols. When you start to implement it, you notice that there are no network layers to help you to hide abstractions. Could we have OSI layer mappings or similar at least? (Please see the chapter The Missing Layer - Fixing The Internet)
Many performance red flags pop up when you start to engineer the implementation. Just think about tail latency in DID resolving and you see it. Especially if you think the performance demand of the DNS. The comparison is pretty fair.
No Need For The Ledger
The did:onion method is currently the only straightforward way to build
self-certified public DIDs that cannot be correlated. The did:web is
analogue, but it doesn’t offer privacy as itself. However, it provides privacy
for the individual agents through herd privacy if DID specification doesn’t
fail in it.
Indy stores credential definitions and schemas to the ledger addition to public DIDs. Nonetheless, when verifiable credentials move to use BBS+ credential definitions aren’t needed and schemas can be read, e.g. from schema.org. Only those DID methods need a ledger that is using a ledger as public DID’s trust anchor and source of truth.
What Is A Public DID?
It’s a DID who’s DIDDoc you can solve without an invitation.
The did:key is superior because it is complete. You can compute (solve) a DID
document by receiving a valid DID key identifier. No third party or additional
source of truth is needed. However, we cannot communicate with the did:key’s
holder because the DIDDoc doesn’t include service
endpoints. So, there is no one
listening and nothing to connect to.
Both did:onion’s and did:web’s DIDDocs can include service endpoints because
they can offer the DID document by their selves from their own servers. We must
remember that the DID document offers verification
methods which can be used
to build the actual cryptographic
trust.
How To Design Best Agency?
How to do it right now when we don’t have a working standard or de facto specifications? We have thought that for a long time, over three years for now.
I have thought and compared SSI/DID networks and solutions. I think we need to have a layer model similar to the OSI network model to handle complexity. Unfortunately, the famous trust-over-IP picture below isn’t the one that is missing:
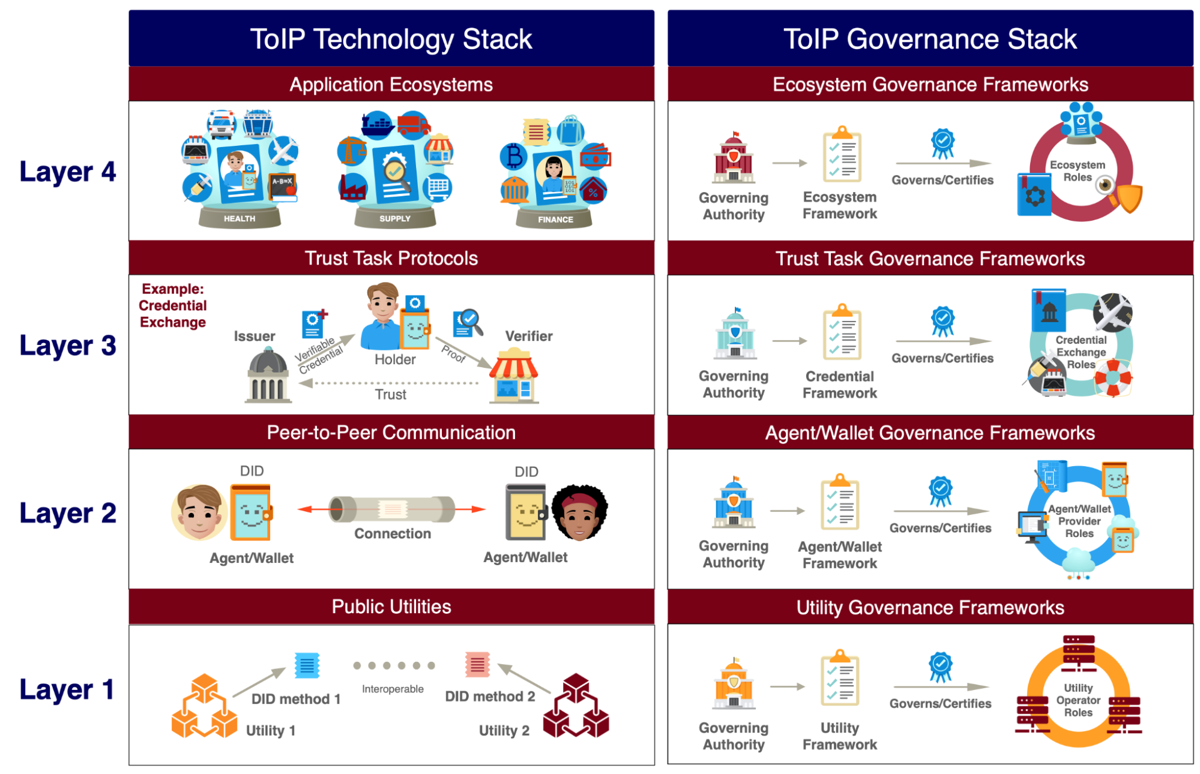
ToIP Stacks
Even though the ToIP has a layer model, it doesn’t help us build technical solutions. It’s even more unfortunate that many in the industry think that it’s the network layer model when it’s not. It’s been making communication between different stakeholders difficult because we see things differently, and we don’t share common ground detailed enough.
Luckily, I found a blog post which seems to be the right one, but I didn’t find any follow-up work. Nonetheless, we can use it as a reference and proof that there exists this kind of need.
The following picture is from the blog post. As we can see, it includes problems, and the weirdest one is the missing OSI mapping. Even the post explains how vital the layer model is for interoperability and portability. Another maybe even more weird mistake is mentioning that layers could be coupled when the whole point of layered models is to have decoupled layers. Especially when building privacy holding technology, it should be evident that there cannot be leaks between layers.

The Self-sovereign Identity Stack - The Blog Post
The Missing Layer - Fixing The Internet
The following picture illustrates mappings from the OSI model through protocols to TCP/IP model.
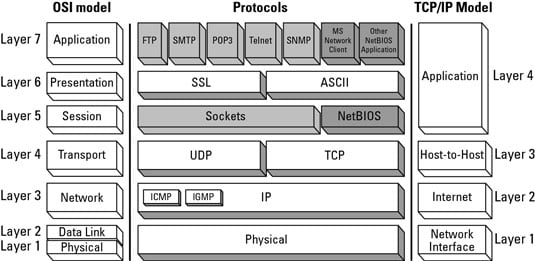
We all know that the internet was created without security and privacy, and still, it’s incredibly successful and scalable. From the layer model, it’s easy to see that security and privacy solutions should be put under the transport layer to allow all of the current applications to work without changes. But it’s not enough if we want to have end-to-end encrypted and secure communication pipes.
We need to take the best of both worlds: fix as much as possible, as a low layer as you can one layer at a time.
Secure & Private Transport Layer
There is one existing solution, and others are coming:
I know that Tor has its performance problems, etc., but the point is not about that. The point is to which network layer should handle secure and private transport. It’s not DIDComm, and it definitely isn’t implemented as statical routing like currently in DIDComm. Just think about it: What it means when you have to change your mediator or add another one, and compare it to current TCP/IP network? It’s a no-brainer that routing should be isolated in a layer.
The following picture shows how OSI and TCP/IP layers map. It also shows one possibility to use onion routing instead on insecure and public TCP/IP routing for DID communication.
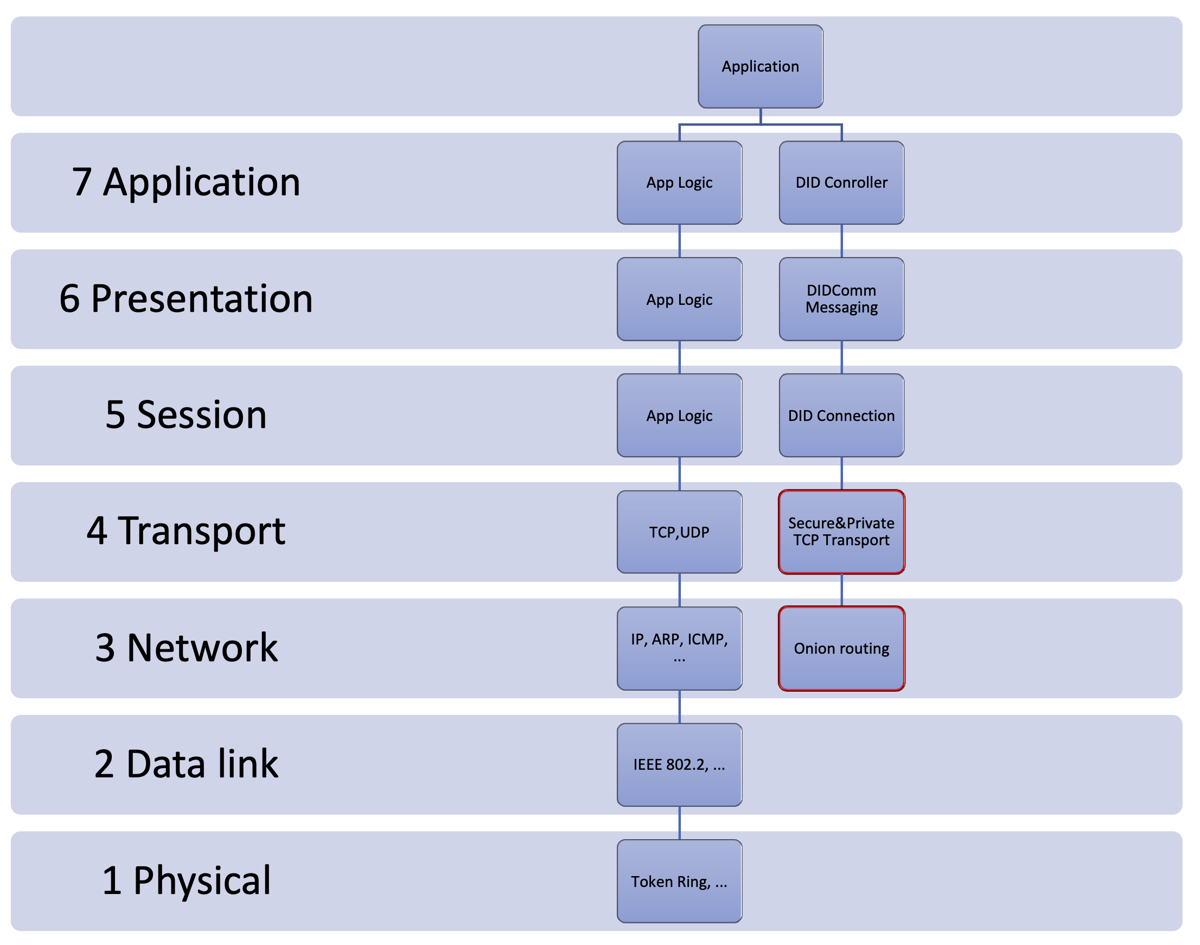
DID Communication OSI Mapping
The solution is secure and private, and there aren’t no leaks between layers which could lead to correlation.
Putting All Together
The elephant is eaten one bite at a time is a strategy we have used
successfully and continue to use here. We start with missing core
concepts: DID, DID document, DID method, DID resolving. The following
UML diagram present our high-level conceptual model of these concepts and their
relations.
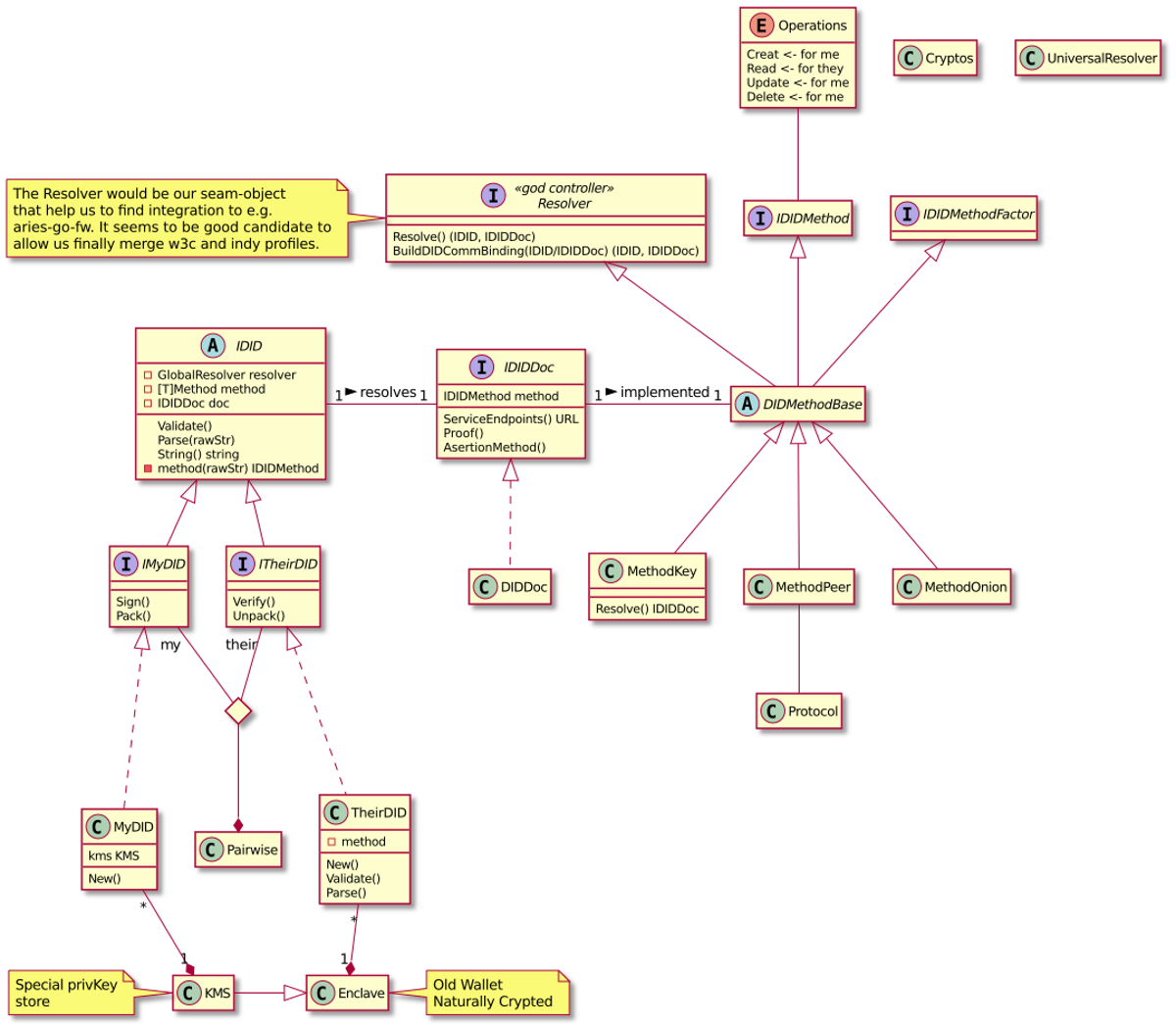
Agency DID Core Concepts
Because current DID specification allows or supports many different DID Methods we have to take care of them in the model. It would be naive to think we could use only external DID resolver and delegate DIDDoc solving. Just for think about performance, it would be a nightmare, security issues even more.
Replacing the Indy SDK
We will publish a separate post about replacing Indy SDK or bringing other Aries solutions as a library. What the basic strategy will be is decided during the work. We’ll implement new concepts and implement only these DID methods during the process:
- DID Key, needed to replace public key references, and it’s usable for many other purposes as well.
- DID Peer, building pairwise connection is a foundation to DIDComm. However,
we are still figuring out the proper implementation scope for
the
did:peer. - DID Web and Onion, it seems that this is an excellent transition method towards
more private and sovereign
did:onionmethod.
Stay tuned. The following blog post is coming out in a week.