Travelogue
The success of our team is measured:
- How well do we understand certain emerging technologies?
- How relevant they are to the business we are in?
- How much potential do they have for our company’s business?
If you are asking yourself if the order of the list is wrong, the answer is, it is not.
We have learned that you will fail if you prioritize technologies by their business value too early. There is a catch, though. You must be sure that you will not fall in love with the technologies you are studying. Certain scepticism is welcomed in our line of work. That attitude may follow thru this post as well. You have now been warned, at least.
Technology Tree
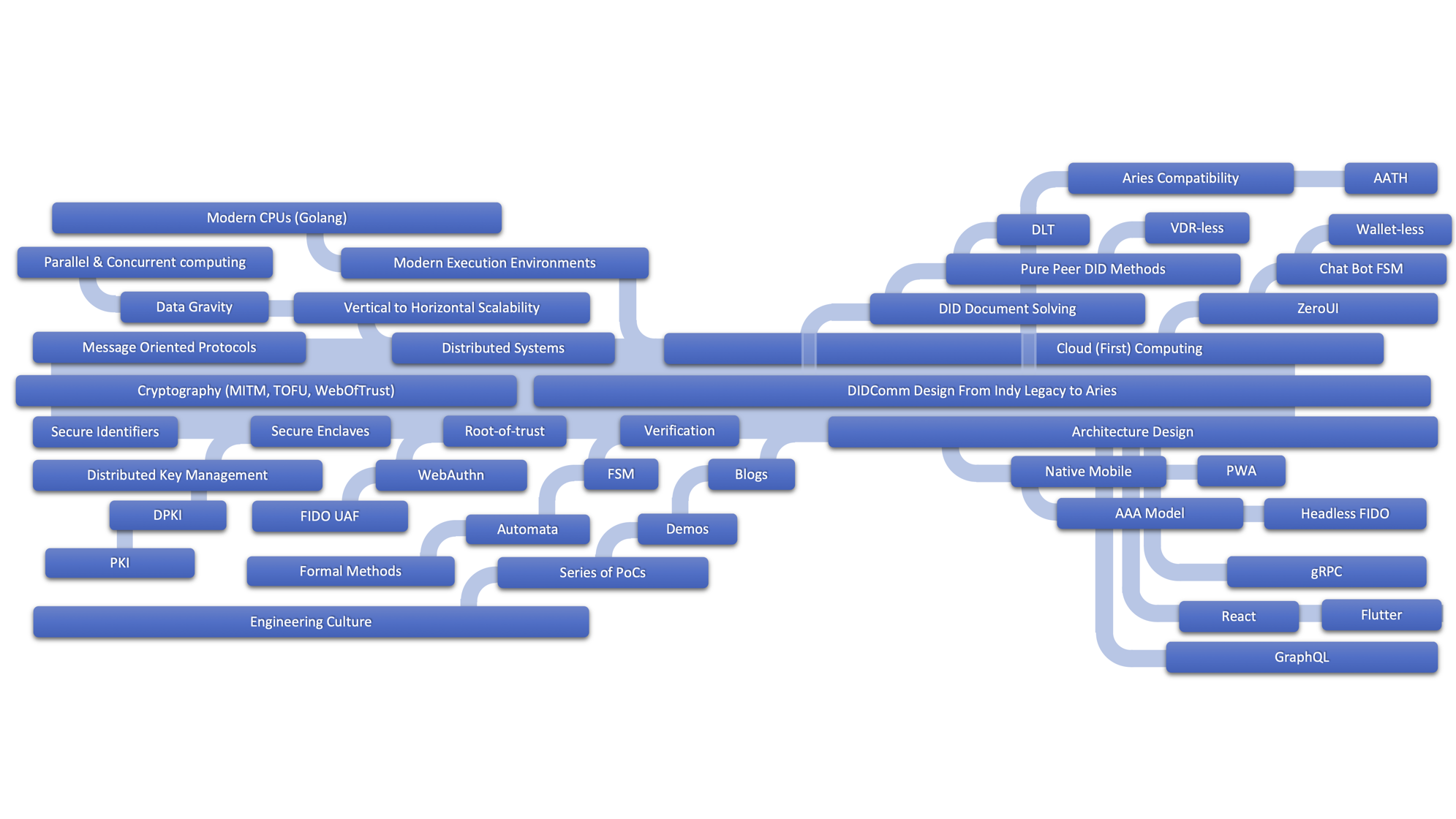
Findy Agency Tech Tree
Technology roots present the most important background knowledge of our study. The most fundamental technologies and study subjects are in the trunk. The trunk is the backbone of our work. It ties it all together. Branches and leaves are outcomes, conclusions, and key learnings. At the top of the tree, some future topics are considered but not implemented or even tried yet.
Even if the technology tree illustrates the relevant technologies for the subject, we will not address them in this post. We recommend you to study the tree for a moment to get the picture. You will notice that there aren’t any mention of VC. For us, the concept of VC is an internal feature of DID system. Naturally, there are a huge amount of enormous study subjects inside VCs like ZKP, etc. But this approach has to lead us to concentrate on the network itself and the structure it should have.
The tree has helped us to see how things are bound together and what topics are the most relevant for the study area.
Trust Triangle
The famous SSI trust triangle is an excellent tool to simplify what is important and what is not. As we can see, everything builds on peer to peer connections, thick arrows. VCs are issued, and proofs are presented thru them. The only thing that’s not yet solved at the technology level is the trust arrow in the triangle. (I know the recursive trust triangle, but I disagree with how it’s thought to be implemented). But this blog post is not about that either.
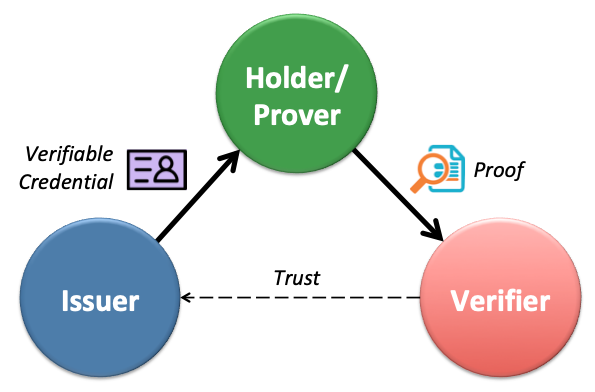
The SSI Trust Triangle
Targets and Goals
Every project’s objectives and goals change during the execution. The longer the project, the more pivots it has. (Note that I use the term project quite freely in the post). When we started to work with DID/SSI field, the goal was to build a standalone mobile app demo of the identity wallet based on Hyperledger Indy. We started in test drive mode but built a full DID agency and published it as OSS. The journey has been inspiring, and we have learned a lot.
In every project, it’s important to maintain the scope. Thanks to the nature of our organisation we didn’t have changing requirements. The widening of the scope came mostly from the fact that the whole area of SSI and DID were evolving. It still is.
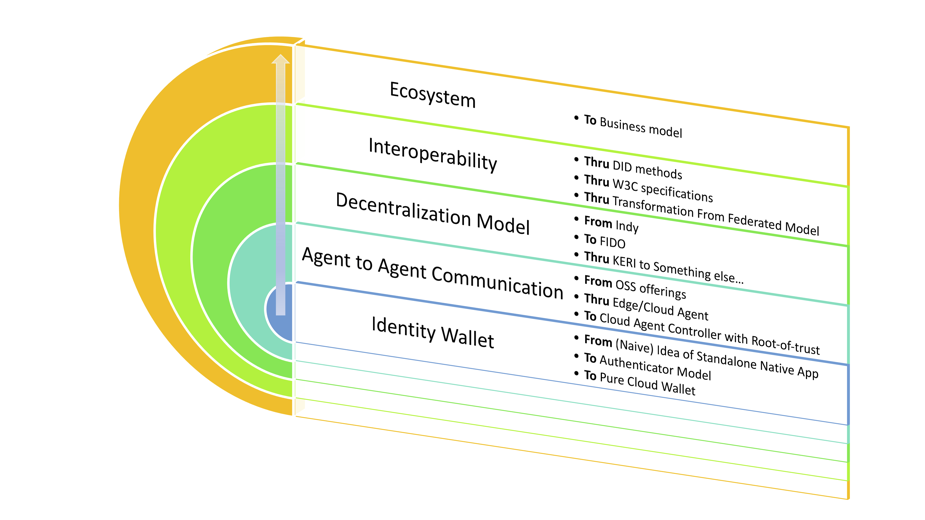
The Journey From Identity Wallet to Identity Ecosystem
Many project goals changed significantly during the execution, but that was part of the job. And as DID/SSI matured, we matured as well, and goals to our work aren’t so test-driven mode anymore. We still test other related technologies that can be matched to DID/SSI or even replace some parts of it but have transited to the state where we have started to build our own related core technologies to the field.
Incubators usually start their trip by testing different hypotheses and trying them out in practice. We did the same but more on the practical side. We didn’t have a formal hypothesis, but we had some use cases and a vision of how modern architecture should work and its scaling requirements. Those kinds of principles lead our decision-making process during the project. (Maybe some of us write a detailed blog about how our emerging tech process and organisation worked.)
The journey
We have been building our multi-tenant agency since the beginning of 2019. During that time, we have tried many different techniques, technologies and architectures, and application metaphors. We think we have succeeded to find interesting results.
In the following chapters, we will report the time period from the beginning of 2019 to autumn of 2021 in half of a year intervals. I really recommend that you look at the timelines carefully because they include valuable outcomes.
2019/H1
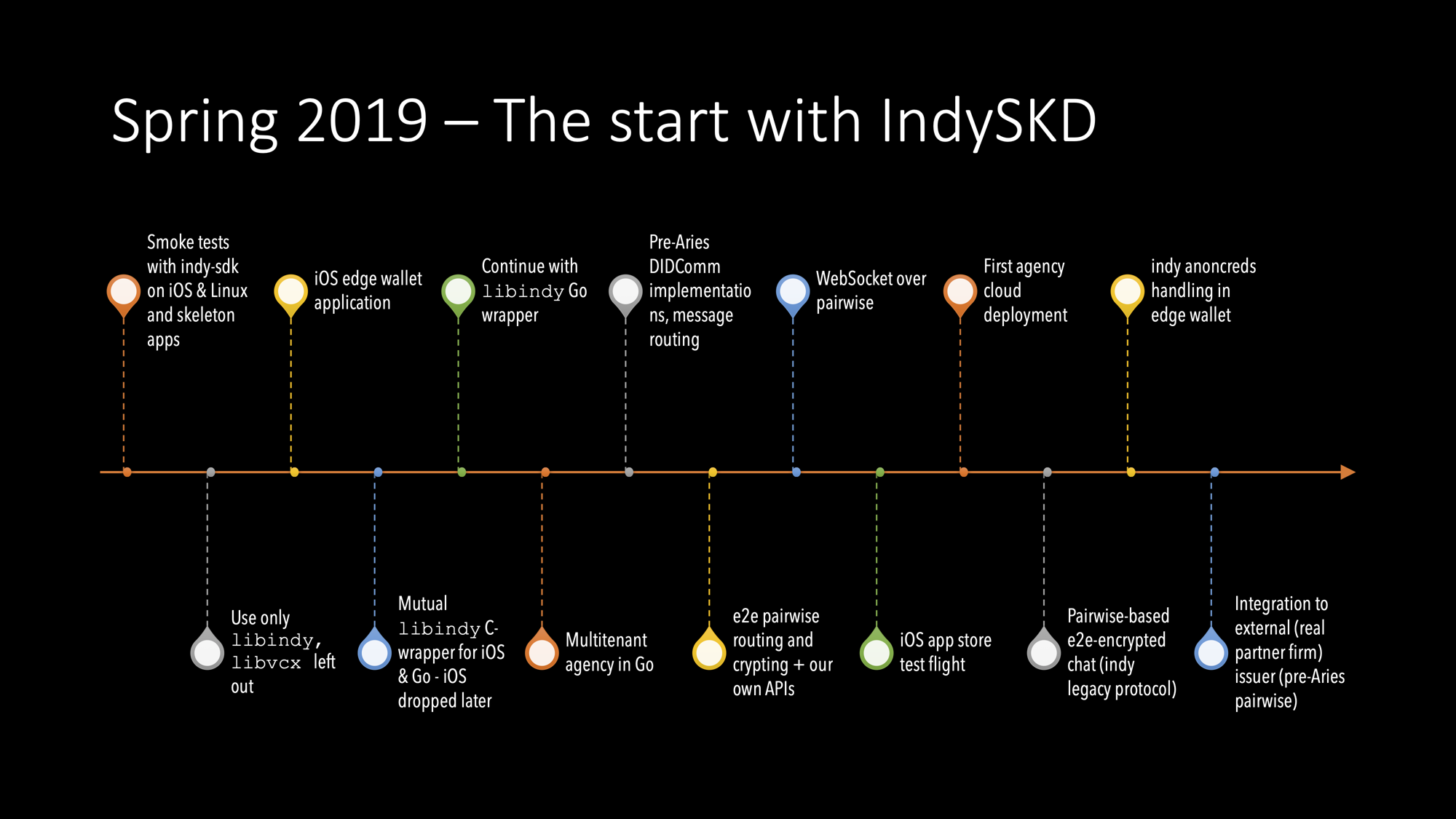
2019/H1
The Start
Me:
“I’m interested in studying new tech by programming with it.”
Some block-chain experts in the emerging technologies team:
“We need an identity wallet to be able to continue with our other projects. Have you ever heard of Hyperledger Indy..”
In one week, I have been smoke-tested indy SDK on iOS and Linux. During the spring, we ended up following the Indy’s proprietary agent to agent protocol, but we didn’t use libcvx for that because:
This library is currently in an experimental state and is not part of official releases. - [indy SDK GitHub pages]
To be honest, that was the most important reason because we have had so much extra work with other Indy libs, and of course, we would need a wrapper at least for Go. It was an easy decision. Afterwards, it was the right because the DIDComm protocol is the backbone of everything with SSI/DID. And now, when it’s in our own (capable) hands, it’s made many such things possible which weren’t otherwise. We will publish a whole new technical blog series of our multi-tenant DIDComm protocol engine.
All of the modern, native mobile apps end up been written from two parts: the mobile app component running on the device and the server part doing everything it can to make the mobile app’s life easier. Early stages, DIDComm’s edge and cloud agent roles weren’t that straightforward. From every point of view, it seemed overly complicated. But still, we stuck to it.
First Results
At the end of spring 2019, we had a quick and dirty demo of the system, which had multi-tenant agency to serve cloud agents and iOS mobile app to run edge agents. An EA onboarded itself to the agency with the same DID Connect protocol, which was used everywhere. Actually, an EA and a CA used Web Sockets as a transport mechanism for indy’s DIDComm messages.
We hated the protocol. It was insane. But it was DID protocol, wasn’t it?
The system was end to end encrypted, but the indy protocol had its flaws, like being synchronous. We didn’t yet have any persistent state machine or the other basics of the communication protocol systems. Also, the whole thing felted overly complicated and old – it wasn’t modern cloud protocol.
Third party integration demo
In early summer ended up building a demo that didn’t follow totally the current architecture, because the mobile app’s edge agent was communicating directly to the third party agent. This gave us a lot of experience, and for me, it gave needed time to spec what kind of protocol the DIDComm should be and what kind of protocol engine should run it.
It was a weird time because indy’s legacy agent to agent protocol didn’t have a public, structured and formal specification of its protocol.
Those who are interested in history can read more from here.
The integration project made it pretty clear for us what kind of protocol was needed.
Async with explicit state machine
DIDComm must be async and message-driven simple because it’s deliberative in its nature. Two agents are negotiating for issuing, proofing, etc.
Aries news
Hyperledger Aries was set up during the summer, which was good because it showed the same we learned. We were on the right path.
Code Delivery For a Business Partner
For this mail-stone, we ended up producing some documentation, mostly to explain the architecture. During the whole project, we have had a comprehensive unit and integration test harness.
At this point, we had all of the important features covered: issuing, holding, present and verify proofs in a quick and dirty way. Now we knew the potential.
Results 2019 Summer
We had managed to implement pre-Aries DIDComm over HTTP and WebSocket. We had a multi-tenant agency running cloud agents even though it was far from production readiness. Everything was end to end encrypted. The current agency supported indy’s ledger transactions, and first, we had taken some tests from issuing and proofing protocols. We started to understand what kind of beast was tearing at us from another end of the road.
2019/H2
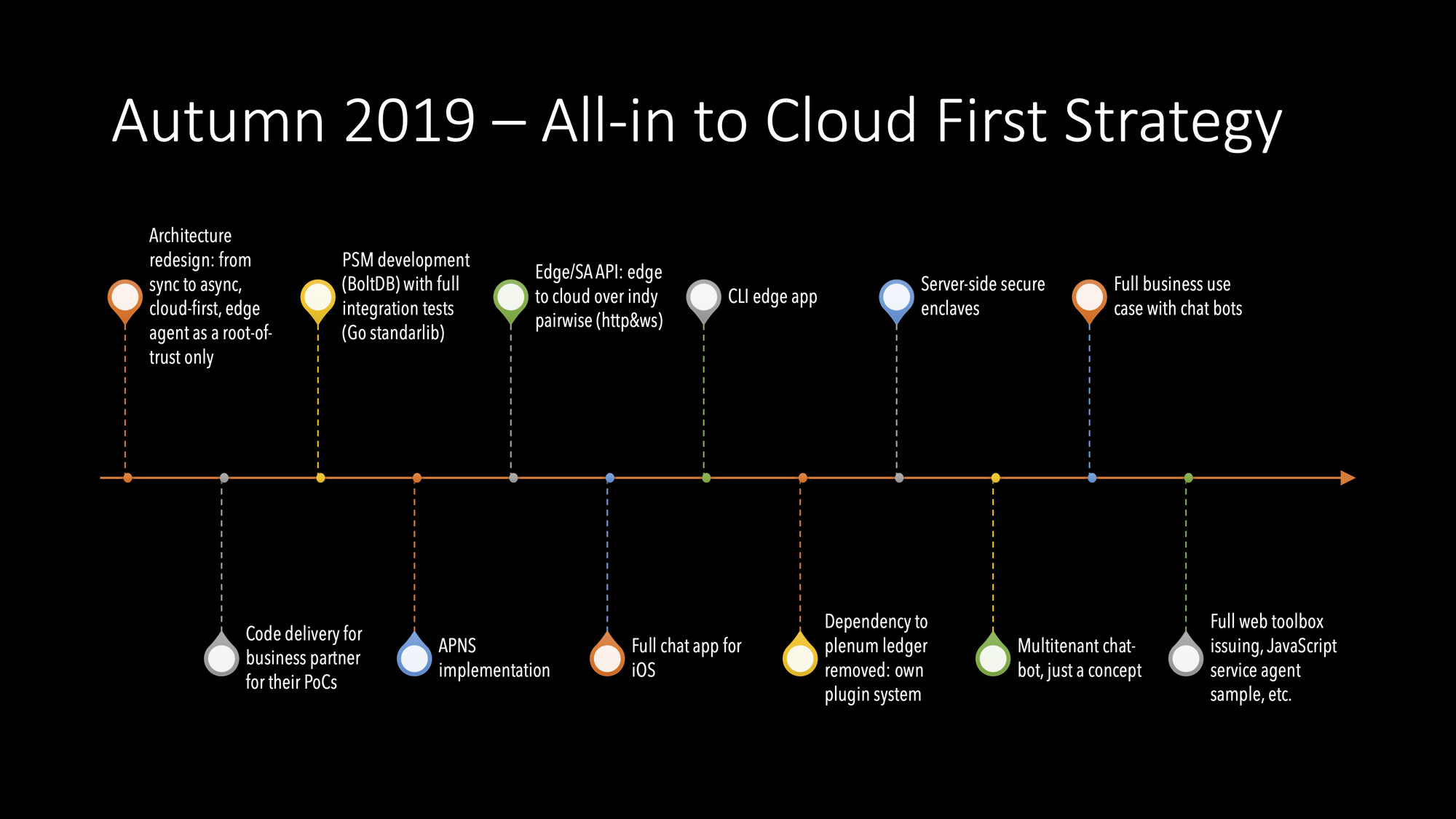
2019/H2
Start Of The Async Protocol Development
When we started architecture redesign after the summer break, we had a clear idea of what kind of direction we should take and what to leave for later:
- Cloud-first and we have newer wanted to step back on that.
- Modern micro-service architecture targeting continuous delivery and scalability. That leads to a certain type of technology stack which consists of techs like Go, gRPC, Docker (or other containerization technology), container orchestration like K8s, etc. One key requirement was that hardware utilization must be perfect, i.e. tiny servers are enough.
- No support for offline use cases for now.
- No revocation until there is a working solution. Credit card revocation has taught us a lot. Scalable and fast revocation is a hard problem to solve.
- Message routing should not be part of the protocol’s explicit ‘headers’, i.e. there is only one service endpoint for a DID. We should naturally handle the service endpoint so that privacy is maintained as it is in our agency. By leaving routing out, it has been making everything so much simple. Some technologies can do that for us for free, like Tor. We have tested Tor, and it works pretty well for setting service endpoints and also connecting to them.
- Use push notifications along with the WebSockets, i.e. lent APNS to trigger edge agents when they were not connected to the server.
Multi-ledger Architecture
Because everything goes through our Go wrapper to the Plenum ledger, I made a version that used memory or plain file instead of the ledger as a hobby project. It was meant to be used only for tests and development. Later the plug-in architecture has allowed us to have other persistent saving media as well. But more importantly, it has helped development and automatic testing a lot.
Technically the hack is to use pool handle to tell if the system is
connected to a ledger or some other predefined media. indy API has only two
functions that take pool handle as an argument but doesn’t use it at all or
a handle is an option.
Server Side Secure Enclaves
During the server-side development, we wanted to have at least post-compromised secured key storage for cloud servers. Cloud environments like AWS give you managed storage for master secrets, but we needed more when developing OSS solutions with high performance and scalability requirements.
Now we store our most important keys for LMDB-based fast key-value storage fully encrypted. Master keys for installation are in a managed cloud environments like AWS, Google, Azure, etc.
First Multi-tenant Chat Bot
The first running version of the chatbot used a semi-hard-coded version.
It supported only sequential steps: a single line in a text file,
CredDefIds in its own file, and finally text messages in its own files. The
result was just a few lines of Go code, thanks to its concurrent model.
The result was so good that I made a backlog issue to start studying to use SCXML or some other exciting language for chatbot state machines later. About a year later, I implemented a state machine on my own with a proprietary YAML format.
But that search isn’t totally over. Before that, I considered many different options, but there wasn’t much of an OSS alternative. One option could be to embed Lua combined with the current state machine engine and replace the memory model with Lua. We shall see what the real use case needs are.
I personally think that an even more important approach would be a state machine verifier. Keeping that as a goal sets strict limits to the computation model we could use. What we have learned now is you don’t need the full power of general programming language but finite state machine (automata theory) could just be enough.
2019/H2 Results
We had implemented all the most important use cases with our new protocol engine. We had an symmetric agent which could be in all of the needed roles of SSI: a holder, an issuer, and a verifier. Also, the API seemed to be OK at a high level of abstraction. The individual messages were shit.
At the end of the year, we also had a decent toolbox both on command-line and especially on the web.
2020/H1
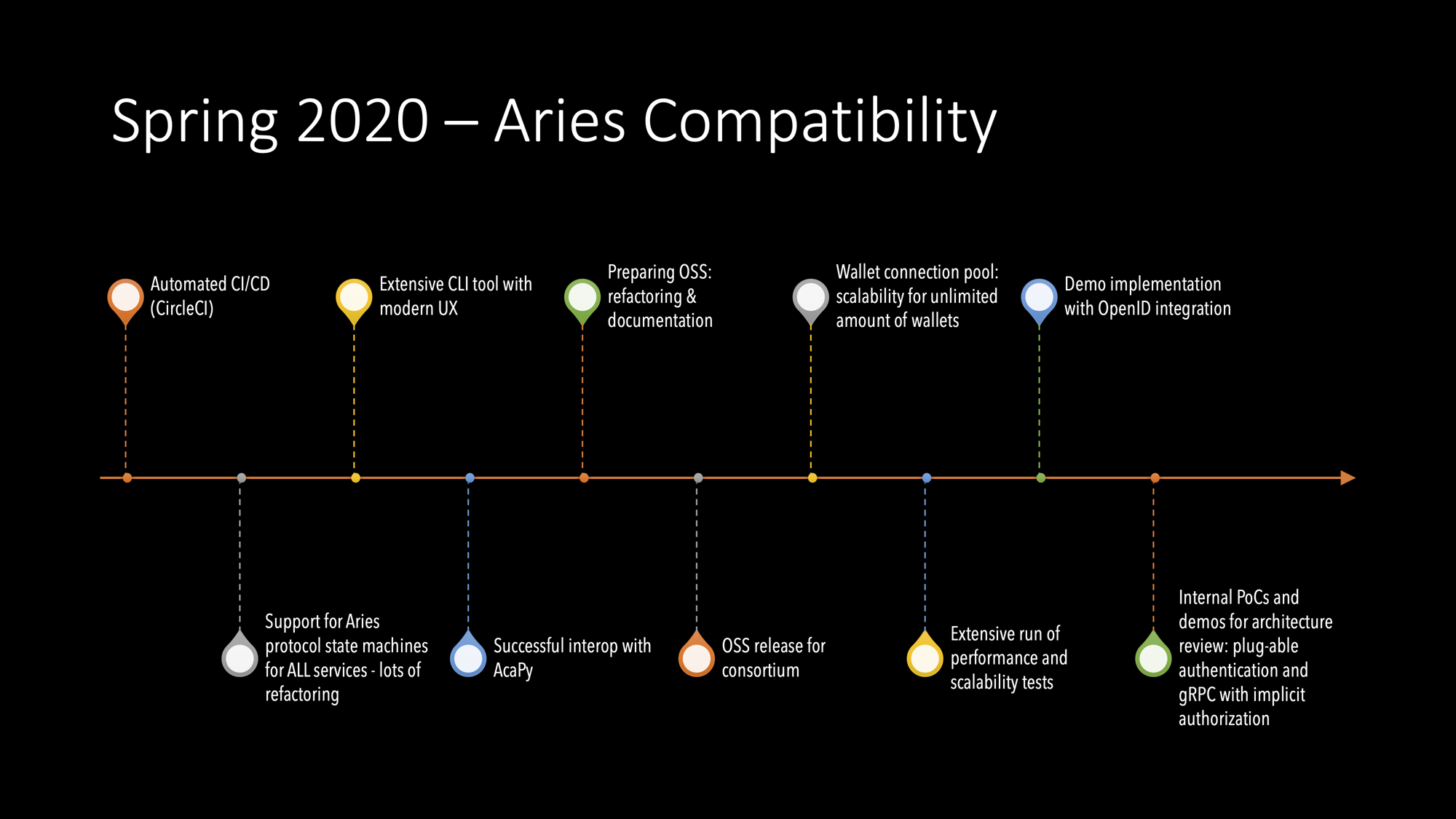
2020/H1
Findy-consortium Level OSS Publication
At the beginning of 2020, we decided to publish all the produced code inside the Findy consortium. We produced the new GitHub account, and code without history moved from original repos to new ones.
Even the decision brought a lot of routine work for that moment, it also brought many good things:
- refactoring,
- interface cleanups,
- documentation updates.
ACA-Py Interoperability Tests
We implemented the first version of the new async protocol engine with existing JSON messages came from legacy indy a2a protocols. It’s mostly because I wanted to build it in small steps, and it worked pretty well.
Most of the extra work did come from the legacy API we had. JSON messages over indy’s proprietary DIDComm. As always, some bad but some good: because we had to keep both DIDComm message formats, I managed to integrate a clever way to separate different formats and still generalise with Go’s interfaces.
New CLI
We noticed that Agency’s command-line UI started to be too complicated. Go has a clever idea of how you can do services without environmental variables. I’m still the guy who would stick with that, but it was a good idea to widen the scope to make our tools comfortable for all new users.
Our design idea was to build CLI, which follows subcommands like git and docker nowadays. The latest version we have now is quite good already, but the road was rocky. It is not easy to find the right structure the first time. The more you use your CLI by yourself, the more you start to notice what is intuitive and what is not.
We decided to separate CLI commands from Agency to own tool and git repo. It was good to move for that time, and when we managed to make it right, we were able to move those same commands pack to the agency one year later because we needed CLI tool without any libindy dependencies. That is a good example of successful software architecture work. You cannot predict the future, but you can prepare yourself for change.
2020/H2
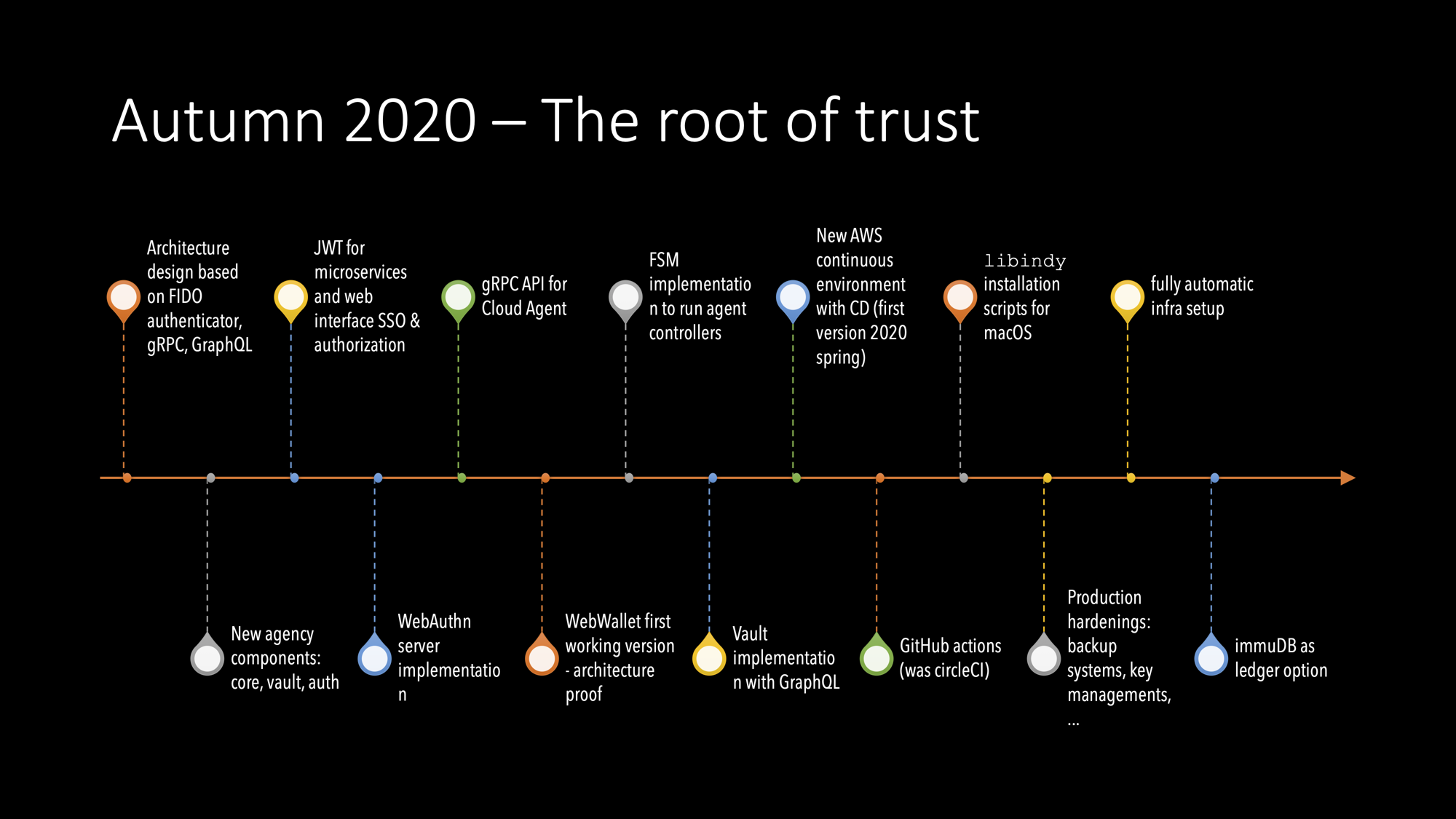
2020/H2
Architecture Planning
I had had quite a long time the idea of using gRPC for the Cloud Agent controller. My core idea was to get rid of the EA because, currently, it was just an onboarding tool. The wallet had, included only the pairwise DID to its cloud agent, nothing else. The actual wallet (we called it worker edge agent wallet) was the real wallet, where the VCs were. I went thru many similar protocols until I found FIDO UAF. The protocol is similar to DIDComm’s pairwise protocol, but it’s not symmetric. Another end is the server, and the other has the authenticator – the cryptographical root of trust.
When I presented an internal demo of the gRPC with the JWT authorization and explained that authentications would be FIDO2 WebAuthn, we were ready to start the architecture transition. Everything was still good when I implemented the first FIDO server with the help of Duo Labs Go packages. Our FIDO2 server was now capable of allocating cloud agents. But there was one missing part I was hoping someone in the OSS community would implement until we needed it. It was a headless WebAuthn/UAF authenticator for those issuers/verifiers running as service agents. How to onboard them, and how they would access the agency’s resources with the same JWT authorization? To allow us to proceed, we added support to get JWT by our old API. It’s was only intermediated solution but served its purpose.
Learnings when implementing the new architecture
- implicit JWT authorization helps gRPC usage a lot and simplifies it too.
- gRPC streams and Go’s channel is just excellent together.
- You should use pre-generated wallet keys for indy wallets.
- We can integrate performance and scalability tests into CI.
- gRPC integration and unit testing could be done in the same way as with HTTP stack in Go, i.e. inside a single process that can play both client and server.
Highlights of the end of the year 2020
We started to build for new SA architecture and allowed both our APIs to existing. WebAuth server, headless authenticator, and Vault first versions were now ready. Also, I did the first version of a state machine for service agent implementation. We had an option to use immuDB instead of Plenum ledger.
2021/H1
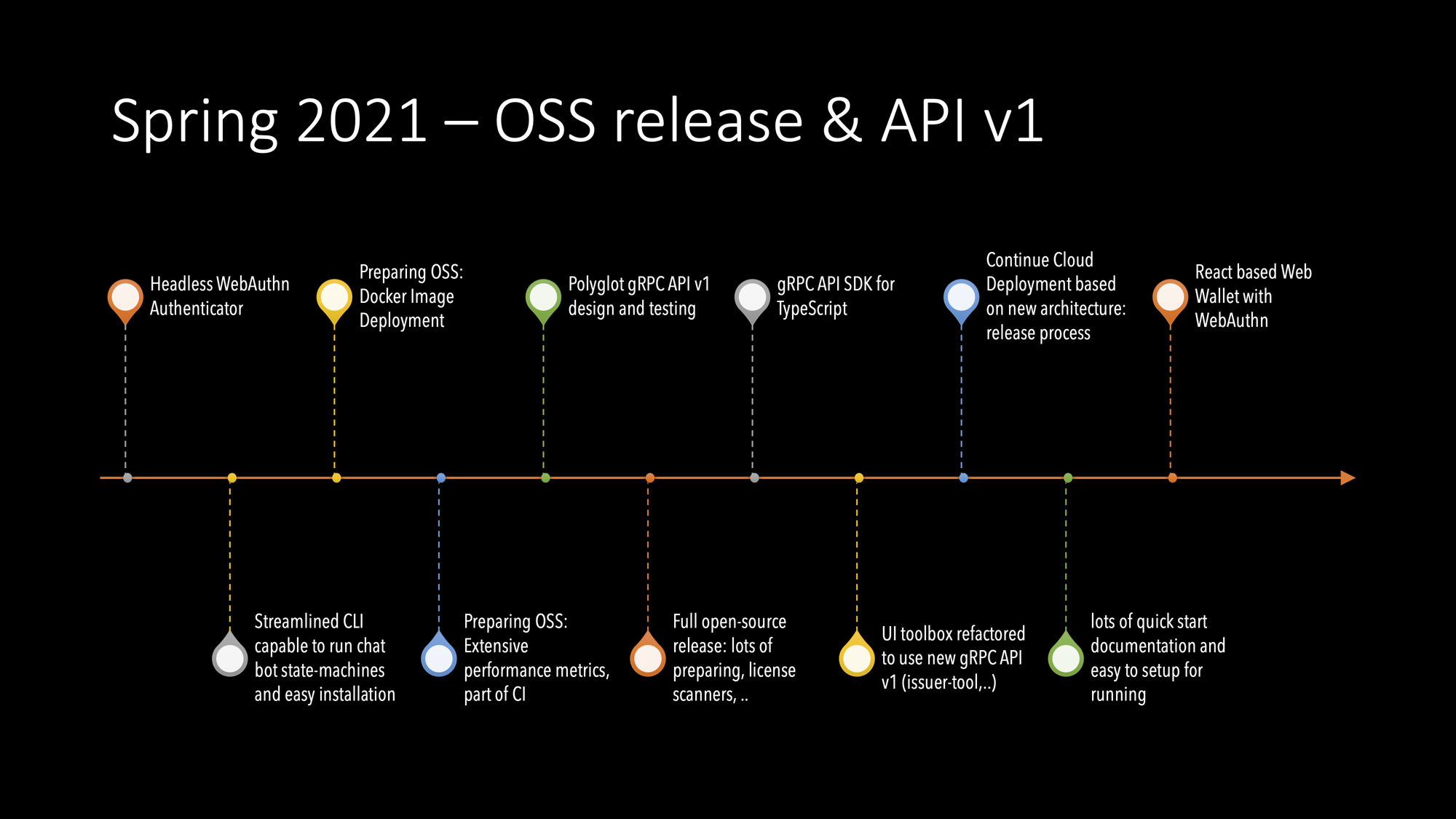
2021/H1
Now we have an architecture that we can live with. All the important elements are in place. Now we just clean it up.
Summary of Spring 2021 Results
Until the summer, the most important results have been:
- Headless WebAuthn authenticator
- React-based Web Wallet
- Lots of documentation and examples
- Agency’s gRPC API v1
- Polyglot implementations gRPC: TypeScript, Go, JavaScript
- New toolbox both Web and Command-line
- The full OSS release
As said, all of the important elements are in place. However, our solution is
based on libindy, which will be interesting because the Aries group moves to
shared libraries, whereas the original contributor continues with it. We haven’t
made the decision yet on which direction we will go. Or do we even need to
choose? At least in the meantime, we could add some new solutions and run them
both. Thanks to our own architecture and interfaces, those are plausible options
for our agency.
There are many interesting study subjects we are continuing to work on within SSI/DID. We will report them in upcoming blog posts. Stay tuned, folks!